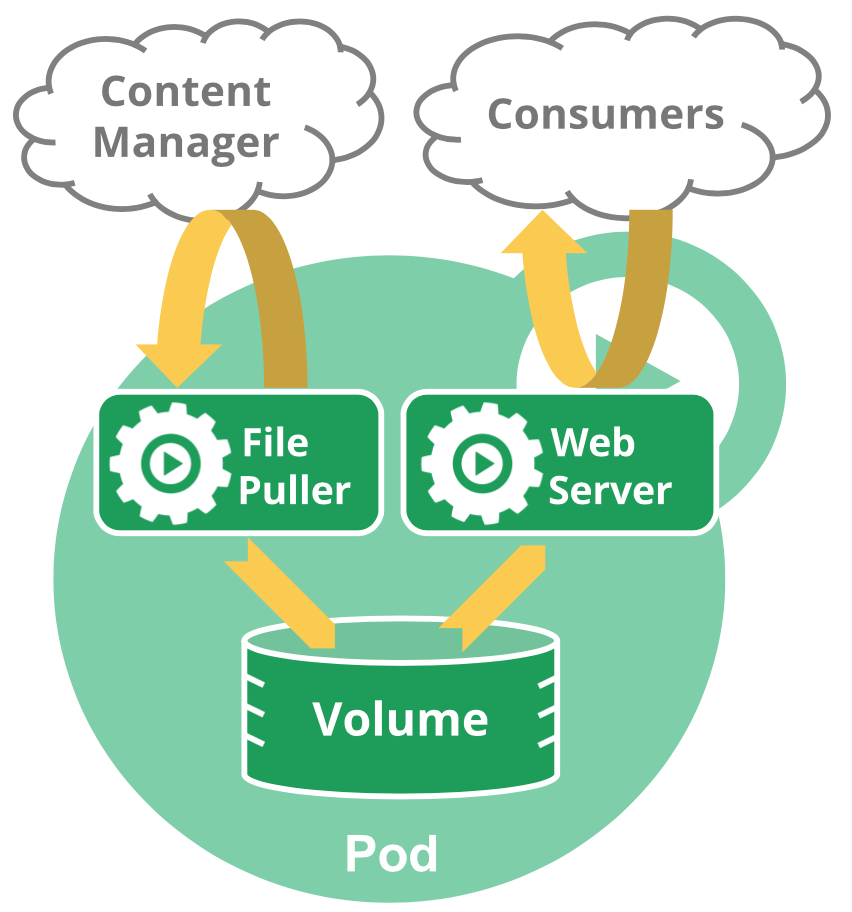
Pod内containers
Pod内有一个或者多个container,共享networking(IP/Port)和storage(每个Pod可以定义一个或多个Pod内containers共享的storage volumes)。
pod-to-pod
Kubernetes规定Pod/Node通讯必须满足以下要求:
- Pods on a node can communicate with all pods on all nodes without NAT
- Agents on a node (e.g. system daemons, kubelet) can communicate with all pods on that node
- Pods in the host network of a node can communicate with all pods on all nodes without NAT
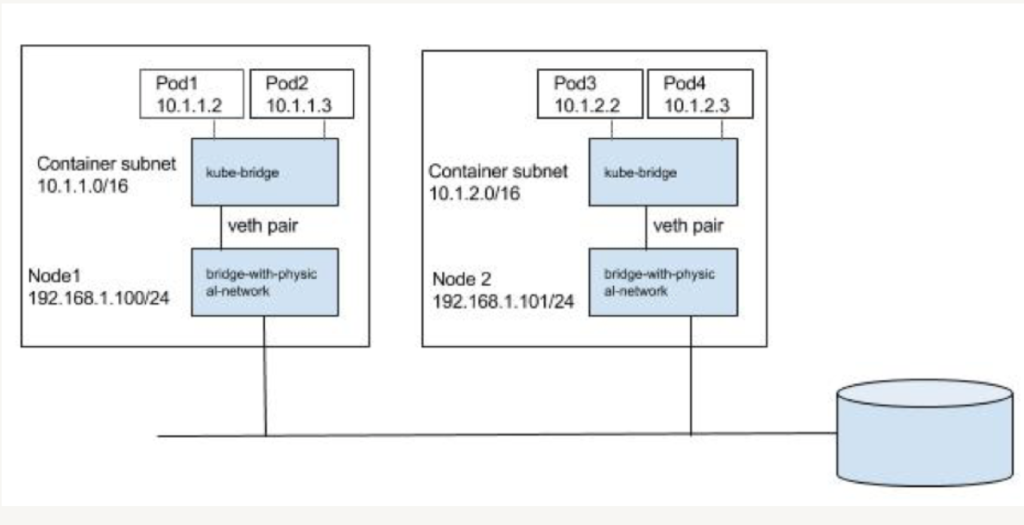
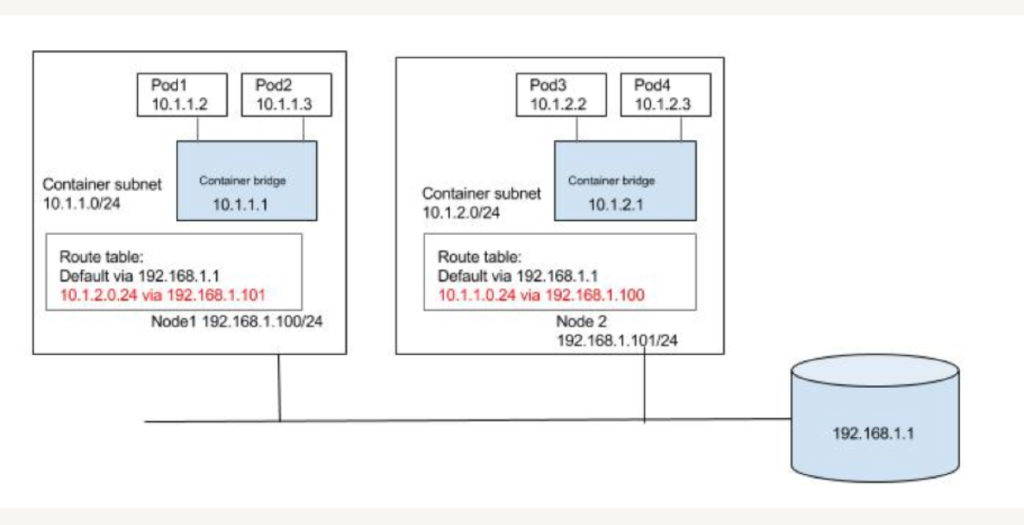
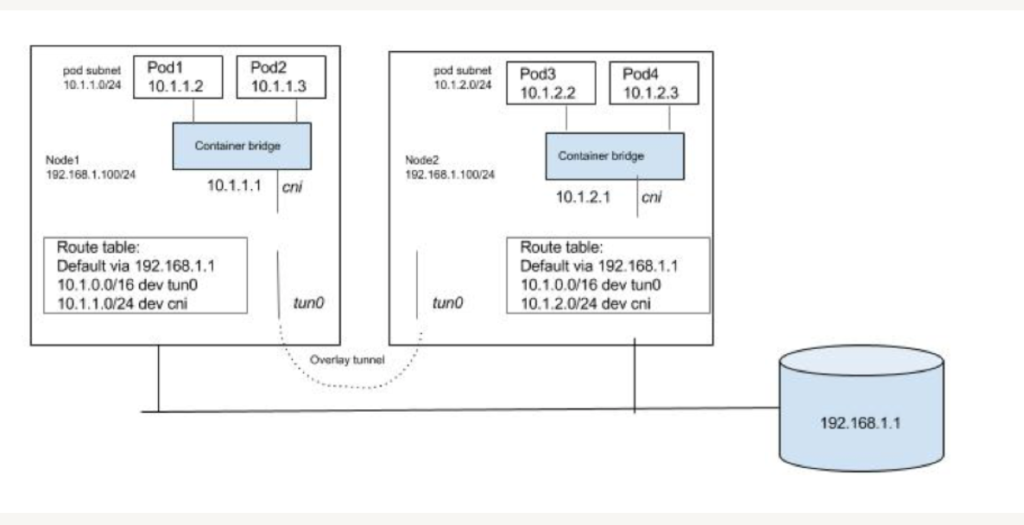
Kubernetes/Containers依赖于Linux namespace来隔离系统资源:process, networking, mount, user etc。每个Pod有自己的network namespace,Pod和Pod外的设备交互需要通过veth paires(虚拟网卡对)来实现,分别连接到Pod和Host的network namespace,那么Pod是怎么和外界尤其是不同Node的Pod交互的呢,Kubernetes没有自己实现或者限定某种方案,所有的工作都交给CNI plugin,比如Flannel,Open vSwtich等。CNI plugin会创建虚拟网卡对,并给Pod网络空间分配一个IP。CNI plugin会运行在每个node上,路径是/opt/cni/bin,配置文件在/etc/cni/net.d。
归纳起来,CNI plugins可以通过如下三种方式实现Pod间的网络通信,可参考这篇文章。
- Layer 2 solution (switching)
- Layer 3 solution (routing)
- Overlay solution
service
ClusterIP
一个应用部署在pod,当然可以被其他pod访问,可是pod不是常态的存在,会被销毁创建,因此某个应用的IP是会变化的,这对于应用互相调用来说非常不友好。那么怎么解决呢?答案就是service。一个service会有一个ClusterIP (Virtual IP),对应着一个或者多个pod,etcd保存这样一个映射表。当某个service的pod创建后,kubelet会把pod IP上传到etcd。每个node上的kube-proxy会监听service信息,并在其所在的node上配置iptables规则,当有流入的访问(访问ClusterIP)时,会将流量导向相应的pod,默认规则是round-robin。
kube-proxy Every node in a Kubernetes cluster runs a kube-proxy. kube-proxy is responsible for implementing a form of virtual IP for Services of type. Kubernetes relies on proxying to forward inbound traffic to backends.注意这里是用proxy引导service访问请求到后面的pod。有三种proxy方式:space proxy mode, iptables proxy mode, and ipvs proxy mode. 前两种用iptables rules来传递network traffic, 这样的好处是using iptables to handle traffic has a lower system overhead, because traffic is handled by Linux netfilter without the need to switch between userspace and the kernel space。第三种性能更好,因为利用netfilter hook钩子来引流,运行在kernel space。IPVS proxy mode的balancing options:
rr: round-robinlc: least connection (smallest number of open connections)dh: destination hashingsh: source hashingsed: shortest expected delaynq: never queue
Headless 有时候不需要VIP,可以这样设置ClusterIP: None,这时每个Pod都有DNS记录,通过DNS找到的是Pod IP。可以与StatefulSet等结合使用,参考这个例子。
DNS
服务治理需要服务注册,发现和loadbalance。上面讲到了,service/pod的注册信息是由kubelet来维护的,那么服务发现可以通过ClusterIP,但也不太理想,因为IP也可能会变化,可以用dns?是的,kubernetes正是用了DNS(Kubernetes DNS)来彻底解决内部服务发现的。Kubernetes DNS schedules a DNS Pod(or more) and Service on the cluster, and configures the kubelets to tell individual containers to use the DNS Service’s IP to resolve DNS names.
至此,集群内访问service没什么障碍了,那集群外是怎么访问到一个service呢?有几种途径,NodePort,Loadbalancer,和Ingress.
NodePort
如果Service Type为NodePort,那么这个service创建时会打开node的某个Port(30000~32767),该node会监听这个Port,将访问引导至后端的某个pod,当然也是借助于kube-proxy来寻找pod的,访问URI为NodeIP:Port。Kubenetes会打开所有node或者指定node上的同一个Port,因此访问一个service不止一个NodeIP。这里可以考虑再加一层loadbalancer。
当流量从Pod走向cluster外时,Pod IP会通过NAT转化为NodeIP,当流量从外部流入时,DNAT(Destination NAT)转化访问目的地为某个Pod。
LoadBalancer
公有云提供商会提供load balancer,一个load balancer会有一个公网IP。Service Type为LoadBalancer的Service本质还是NodePort类型,但多了一层load balancer,因此service的访问更加方便。
所以每个service需要一个公网IP,或者一个公网域名,如果有很多service,显然这样不太合理。所以Kubernetes引入了Ingress。
自己也可以搭建Kubernetes的load balancer,MetalLB是一种实现方案。
Ingress
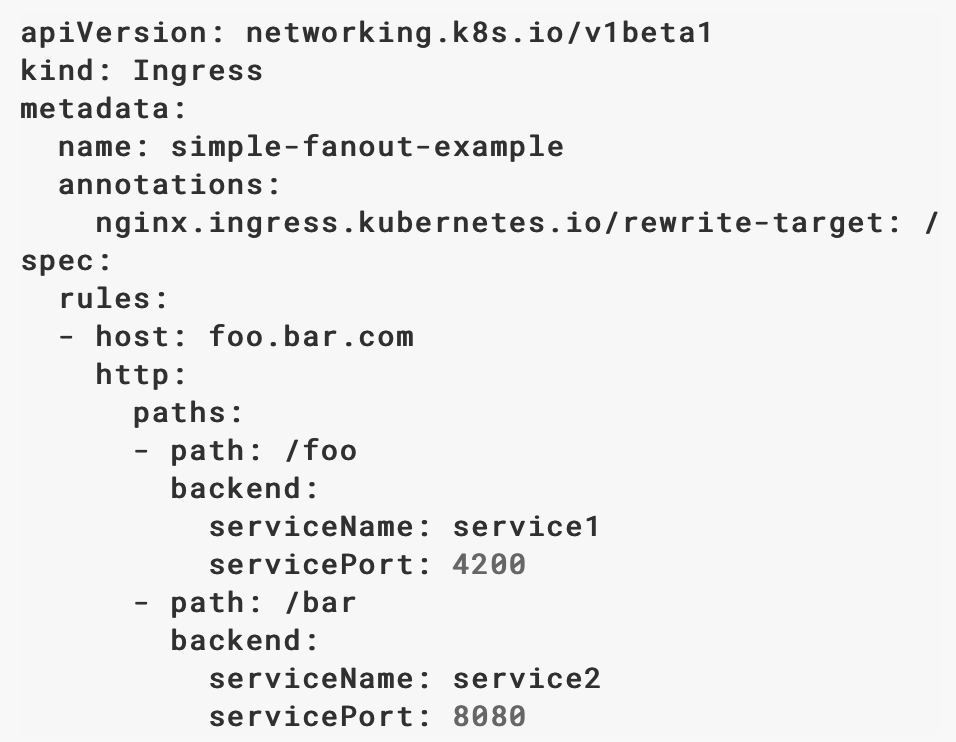
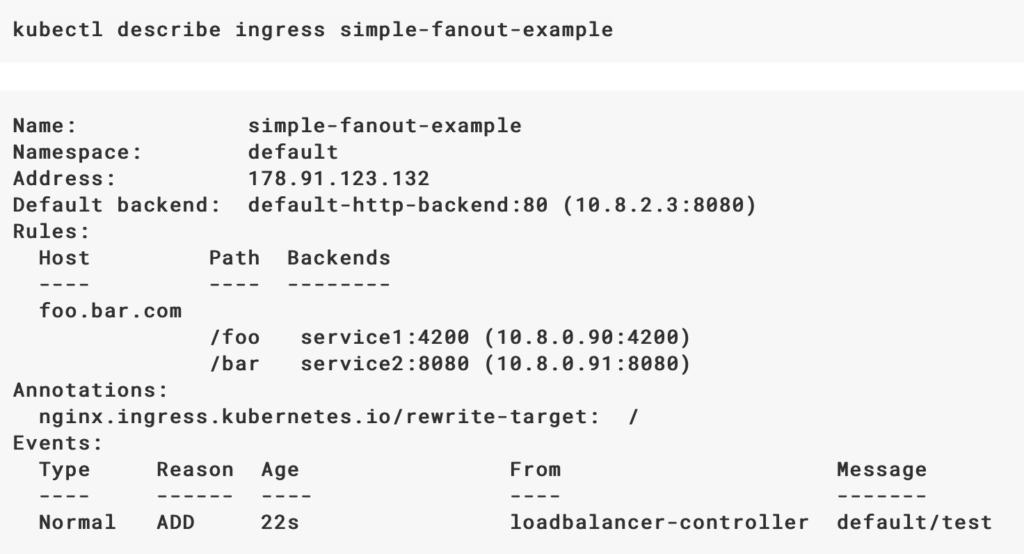
Ingress 实际上是一种反向代理,映射URI(outside cluster)到Service上。可以定义Ingress object, kind: Ingress,ingress.spec定义host/url和backend的映射关系,ingress controller实现这种代理。所以,如果用Ingress,需要有Ingress Controller,比如ingress-nginx和haproxy-ingress,可多可查Ingress controllers。
ingress-nginx是Kubernetes ingress controller, 用ConfigMap来存放Nginx配置。注意的是ingress-nginx controller会在必要时重启nginx,比如当configuration有变动时,但有些情况不用重启,比如upstream(end points)有变动(pod删除,创建),实现方式是通过lua-nginx-module。
进一步探究Ingress。Ingress是一种特殊的service,对外端口为80/443,区别于一般的NortPort。Ingress在外层可对接load balancer(公网IP/域名),也可以用用HostPort对外暴露服务。
如果Cloud Provider支持Loadbalance,直接运行命令即可获取一个loadbalancer的IP。然后创建一个Kind: Ingress配置upstream即可。
$helm install –name nginx-ingress –namespace kube-system stable/nginx-ingress
也可以通过hostPort来暴露Ingress,用DaemonSet方式部署。Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
首先选取一个或者多个Node部署Ingress Controller,然后helm安装到这些Node。安装后即可通过Node IP(80/443)来访问Ingress。如果这些节点有公网IP可以绑定DNS来对外提供服务。
$kubectl label node node_name node=ingress
$helm install stable/nginx-ingress \
–namespace kube-system \
–name nginx-ingress \
–version=xxx \
–set controller.kind=DaemonSet \
–set controller.daemonset.useHostPort=true \
–set controller.nodeSelector.node=ingress \
–set controller.service.type=ClusterIP
Ingress对内通过反向代理对接不同的service。举个例子,假设Ingress配置为两个应用foo.example.com和example.com/abc的代理,当客户访问foo.example.com时,访问请求通过load balancer导向Ingress,Ingress通过配置(path/service映射)找到相应的Service,接下来通过Kube-proxy找到某个Pod。访问example.com/abc时会有一样的流程,只是Ingress的Path不同。
network policy
networkpolicy允许自定义特殊的pod-to-pod,比如定义一个network policy,令某个pod不能被其它pod访问。
Pingback: cialis 85